Una app de Android típica consta de varios componentes de la app, como:
La mayoría de estos componentes los declaras en el manifiesto de la app.
Una app Android no se comporta como una Aplicación de escritorio, es mucho más dinámica. Puede contener varios componentes y los usuarios pueden interactuar con diferentes apps, por lo que éstas deben estar preparadas adaptarse a distintos tipos de tareas y flujos de trabajo controlados por los usuarios en la misma y entre distintas Apps. El S.O. Android nos ayudará a mantener este control desde nuestra App. Además, los dispositivos móviles tienen restricciones de recursos, de manera que, en cualquier momento, el sistema operativo podría cerrar algunos procesos de apps para hacer lugar para otros.
Según las condiciones de este entorno, es posible que los componentes de tu app se inicien de manera individual y desordenada, además de que el usuario o el sistema operativo podrían destruirlos en cualquier momento debido a que no puedes controlar estos eventos.
Por tanto, no debes almacenar ni mantener en la memoria ningún estado ni datos de la aplicación en los componentes de tu app, y estos elementos no deben ser interdependientes.
La Arquitectura
la arquitectura de software empresarial siempre evoluciona con estilos arquitectónicos avanzados para encontrar mejores patrones para construir software de una manera rápida y confiable.
Es importante definir una arquitectura para las aplicaciones de Android porque ha habido un crecimiento notable de aplicaciones en los últimos años.
La arquitectura de la aplicación de Android juega un papel esencial en los siguientes problemas:
- Escalar la aplicación,
- Mejorar la solidez de la aplicación
- Hacer que la aplicación sea más fácil de probar.
Google ha sugerido algunas pautas y prácticas útiles para desarrollar aplicaciones de Android de alta calidad con una arquitectura eficiente en la práctica
Hemos dicho antes que no debes usar los componentes de la aplicación para almacenar datos y estados, entonces
¿Cómo deberías diseñarla?
A medida que crece el tamaño de las apps para Android, es importante definir una arquitectura que permita que esta crezca, aumente su solidez y facilite su prueba.
La arquitectura de una app define los límites entre sus partes y las responsabilidades que debe tener cada una.
Debes diseñar la arquitectura de tu app para que cumpla con algunos principios específicos.
Principios comunes de arquitectura
Separación de problemas
El principio más importante que debes seguir es el de separación de problemas.
Un error común es escribir todo tu código en una Activity o un Fragment.
Estas clases basadas en IU solo deberían contener lógica (código) que se ocupe de interacciones del sistema operativo y de IU. Si mantienes estas clases tan limpias como sea posible, puedes evitar muchos problemas relacionados con el ciclo de vida de los componentes y mejorar la capacidad de prueba de estas clases.
Ten en cuenta que las implementaciones de Activity y Fragment no son de tu propiedad, sino que estas solo son clases que representan el contrato entre el SO Android y tu app. El SO puede destruirlas en cualquier momento en función de las interacciones de usuarios y otras condiciones del sistema, como memoria insuficiente.
Cómo controlar la IU a partir de modelos de datos
Otro principio importante es que debes controlar la IU a partir de modelos de datos, preferentemente que sean de persistencia (no en memoria ni red).
Los modelos de datos representan los datos de una app. Son independientes de los elementos de la IU y otros componentes de la app.
Por lo tanto, no están vinculados a la IU ni al ciclo de vida de esos componentes, pero se destruirán cuando el SO decida eliminar la app de la memoria.
Los modelos de persistencia son ideales por los siguientes motivos:
- Tus usuarios no perderán datos si el SO Android destruye tu app para liberar recursos.
- Tu app continúa funcionando cuando una conexión de red es débil o no está disponible.
Única fuente de información
Cuando se define un nuevo tipo de datos en tu app, debes asignarle una Única fuente de información (SSOT, Single Source of Truth).
La SSOT es la propietaria de esos datos, y sólo la SSOT puede modificarlos o mutarlos.
Con ese fin, la SSOT expone los datos con un tipo inmutable y, para modificarlos, expone funciones o recibe eventos a los que otros tipos pueden llamar.
Este patrón trae varios beneficios:
- Centraliza todos los cambios en un tipo particular de datos en un solo lugar.
- Protege los datos para que otros tipos no puedan manipularlos.
- Hace que los cambios en los datos sean más rastreables. Por lo tanto, los errores son más fáciles de detectar.
En una aplicación que prioriza la condición sin conexión, la fuente de información de los datos de aplicación suele ser una base de datos.
En otros casos, la fuente de información puede ser un ViewModel o incluso la IU.
Flujo de datos unidireccional
El principio de fuente de confianza única se suele usar con el patrón de flujo de datos unidireccional (UDF, Unidirectional Data Flow).
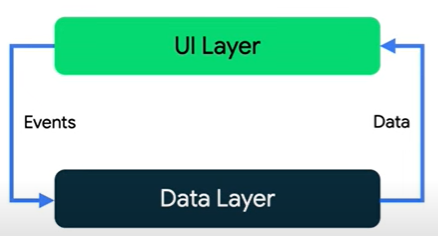
En UDF, el estado fluye en Una sola dirección y los eventos que modifican el flujo de datos en la dirección opuesta.
Por lo general, los eventos se activan desde los tipos de alcance más interior de la IU, y se propagan hasta que alcanzan la SSOT (para el tipo de datos correspondiente).
Los datos de la aplicación generalmente fluyen desde las fuentes de datos hacia la IU.
Los eventos del usuario, como presionar el botón, fluyen desde la IU hasta el SSOT, en el que los datos de la aplicación se modifican y se exponen en un tipo inmutable.
Este patrón garantiza mejor la coherencia de los datos, es menos propenso a errores, es más fácil de depurar y brinda todos los beneficios del patrón de SSOT.
En la imagen anterior, el SSOT está en el Data Layer. Veremos que a su vez el Data Layer se puede descomponer.
Arquitectura de app recomendada
Guía de lectura:
Primero recorre este punto sin entrar en los enlaces específicos al final de cada capa, ya que vamos a ver primero las distintas capas de la arquitectura por encima primero, (UI, Domain, Data) para ver su cometido general.
Después vuelves al enlace de cada capa para ver los detalles de la misma, donde veremos las distintas capas con más profundidad
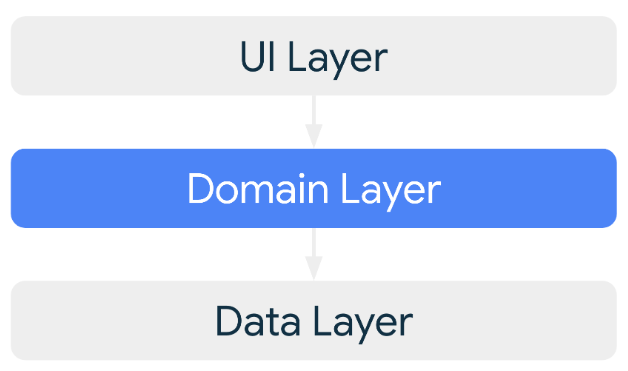
Cada aplicación debe tener al menos dos capas:
- La capa de la IU que muestra los datos de la aplicación en la pantalla.
- La capa de datos que contiene la lógica empresarial de tu aplicación y expone sus datos.
Puedes agregar una capa adicional llamada
- Capa de dominio para simplificar y volver a utilizar las interacciones entre la IU y las capas de datos.
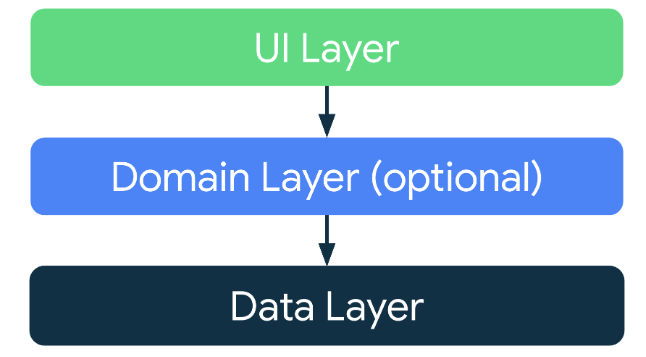
Arquitectura moderna de apps
Esta arquitectura moderna de apps promueve el uso de las siguientes técnicas, entre otras:
- Arquitectura en capas y reactiva
- Flujo unidireccional de datos (UDF) en todas las capas de la app
- Una capa de IU con contenedores de estado para administrar la complejidad de la IU
- Corrutinas y flujos
- Inserción de dependencias
Capa de la IU
La función de la capa de lU (o capa de presentación) consiste en mostrar los datos de la aplicación en la pantalla.
Cuando los datos cambian, ya sea debido a la interacción del usuario (como cuando presiona un botón) o una entrada externa (como una respuesta de red), la IU debe actualizarse para reflejar los cambios.
La capa de la IU consta de dos elementos:
- Elementos de la IU que renderizan los datos en la pantalla (puedes compilar estos elementos con las vistas o las funciones de Jetpack Compose)
- Contenedores de estados (como las clases ViewModel) que retienen datos, los exponen a la IU y controlan la lógica
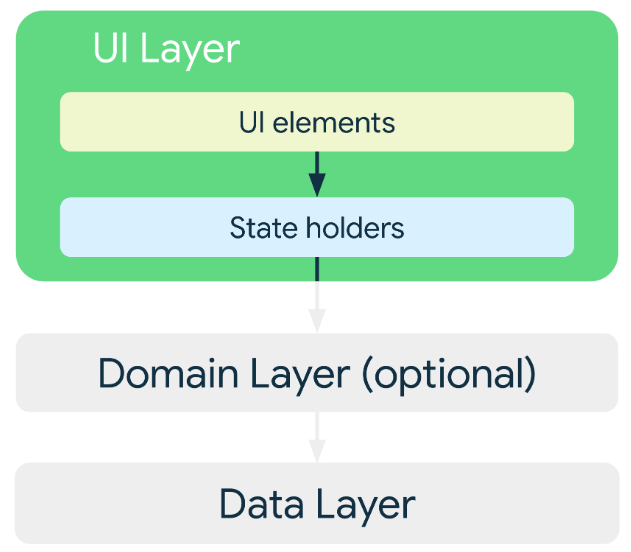
Detalles de la capa UI
Fundamentalmente, la función principal de la capa de interfaz de usuario o capa de presentación es mostrar los datos de la aplicación en la pantalla. Además, sirve como el punto central de la interacción del usuario.
Convención de nomenclatura: funcionalidad + UiState .
La capa de la interfaz de usuario está compuesta de dos conceptos:
- Elementos de la interfaz de usuario
- Estado de la interfaz de usuario
De forma que podemos entender la Interfaz de Usuario = Elementos de Interfaz + Estado de Interfaz
Los elementos de la interfaz de usuario representan los datos en la pantalla.
Por lo tanto, puede crear estos elementos a través de las funciones Views o Jetpack Compose .
El estado de la Interfaz se almacenara en los “State Holders” o almacenadores de estado, los veremos en breve.
La capa de la UI debe realizar los siguientes pasos o acciones:
- Transformar los datos de la aplicación en datos de UI (datos que se verán en la interfaz, puede que necesiten cambios)
- Actualizar los elementos de la interfaz de usuario para reflejar/mostrar estos datos de UI
- Procesar eventos de entrada del usuario (o del sistema, red, etc) que producen cambios en la interfaz de usuario.
- Repetir todos los pasos anteriores tanto tiempo como sea necesario.
Para entender esta secuencia de acciones tenemos que plantearnos los siguientes conceptos en relación al estado:
- ¿Cómo se define el UI state?
- ¿Cómo se crea y gestiona el UI state que hemos definido?
- ¿Cómo se expone/ofrece el UI state mediante tipos de datos Observables (siguiendo el patrón UDF)?
- ¿Cómo implementar un Interfaz de Usuario que consume Observables del UI state?
Definiendo el UI State
Imagina una aplicación de noticias como JetNews (podéis descargarla de su GitHub JetNews) que muestra una lista de noticias de interés cuando el usuario selecciona una categoría y que permite marcarlas como interesantes.
En este caso, la aplicación presenta una lista de artículos, pues bien, la lista de artículos en si misma es el Ui State.
El interfaz de usuario, el UI, es la representación visual del estado del UI.
El UI refleja inmediatamente cualquier cambio que se produzca en el UI State.
Podemos definir el estado de nuestro UI (el UiState) como:
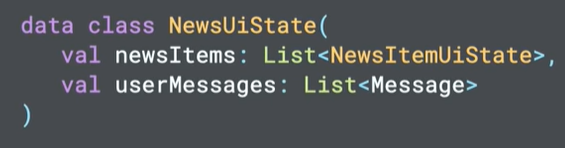
La definición de estado de la interfaz de usuario debe es inmutable.
Esto sirve para mantener el enfoque de que la capa de interfaz de usuario tiene un propósito principal:
Leer el estado y actualizar sus elementos de interfaz de usuario relacionados.
Nunca debes modificar el estado de la interfaz de usuario en la interfaz de usuario directamente (a menos que la propia interfaz de usuario sea la única fuente de sus datos, por ejemplo por inconsistencias y errores)
Creación del UI State
Los datos de la aplicación cambian con el tiempo, debido a interacciones del usuario o actualización de los datos.
Es mejor separar la gestión del UI State en un tipo/objeto distinto del UI.
De esta forma evitamos que el UI sea UI y Gestor del UI State.
Este gestor del UI State es lo que llamamos State Holder (objeto contenedor del estado)
Los StateHolders pueden ser variados y dependen del elemento del UI que produce el estado.
Por ejemplo, para Activities, Fragments o Navigation Destinations el StateHolder principal que se utiliza es el ViewModel.
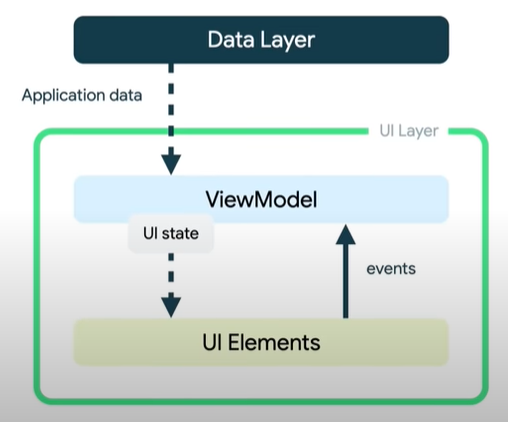
- El ViewModel contiene y expone el estado (UI State) que va a ser consumido por el UI (interfaz de usuario)
- El interfaz de usuario notifica al ViewModel de los eventos de usuario que cambian el estado.
- El ViewModel gestiona los eventos del usuario y actualiza el estado, ofreciéndolo de nuevo al Interfaz de usuario.
- El Interfaz de usuario “consume” el estado (mostrándolo en sus elementos de interfaz)
Esto se repite para cada acción que provoca la mutación del estado.
Hemos visto el principio básico de UDF (Unidirectional Data Flow),
Los eventos “Entran” en el StateHolder (ViewModel) y el estado “Sale” de él.
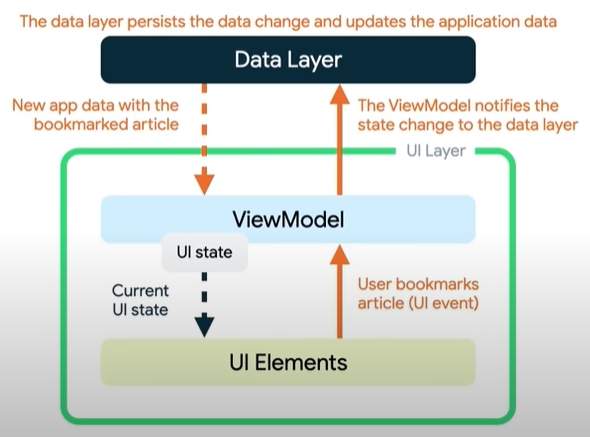
Por ejemplo, en JetNews, cuando un usuario quiere marcar un artículo (como interesante):
El ViewModel primero transforma los datos del DataLayer para que el UI pueda mostrarlos (los extrae, prepara y expone), el UI consume esos datos mostrándolos en sus componentes. El usuario marca un artículo, este evento es enviado al ViewModel que transmite los cambios al Data Layer para que los guarde. Después que el Data Layer procesa la solicitud (de almacenamiento), el UI vuelve a consumir el nuevo UI State que lo muestra al usuario.
Pero, ¿Cómo sabe el UI que el UI State ha cambiado? La clave son los Datos Observables (Observable Data Holders)
El UI State se tiene que exponer en un Observable Data Holder, como pueden ser los State Flow o los Live Data
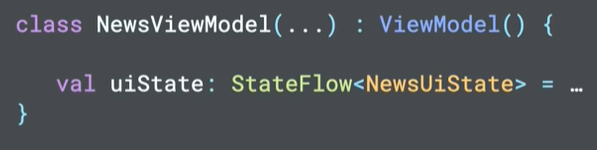
Estos Datos Observables permiten al interfaz de usuario reaccionar a cualquier cambio de estado sin necesidad de acceder y extraer los datos directamente del ViewModel. Estos Datos Observables tienen la última versión del UI State en cache.
Esto (los observables) es muy útil para restaurar el estado después de un cambio de configuración del dispositivo tras una rotación por ejemplo.
También, en aplicaciones con JetPack Compose, se pueden usar también apis como MutableStateOf o SnapshotFlow para la exposición de los eventos de usuario que provocan que el ViewModel mute el estado, puesto que el UI, que está observando el estado, siempre ve la últiima versión actualizada del mismo.
Volviendo al ejemplo de la aplicación de noticas. Supongamos que queremos obtenere las noticias de una categoría.

Definimos el ViewModel (State Holder) que tiene el uiState (lo analizaremos más adelante) y también tiene una referencia a un Job (código) que nos pasarán para realizar la obtención de los datos.
Definimos un método que primero cancela un fetch previo si había uno en progreso y despues lanza una corrutina para traer los nuevos artículos de la categoría pedida. Una vez que han llegado se puede actualizar el UI State. Esos cambios serán llevados automáticamente al UI. Si se producen algunos errores, éstos también deben mostrarse en el UI, por lo que también gestionamos los mensajes en el estado.
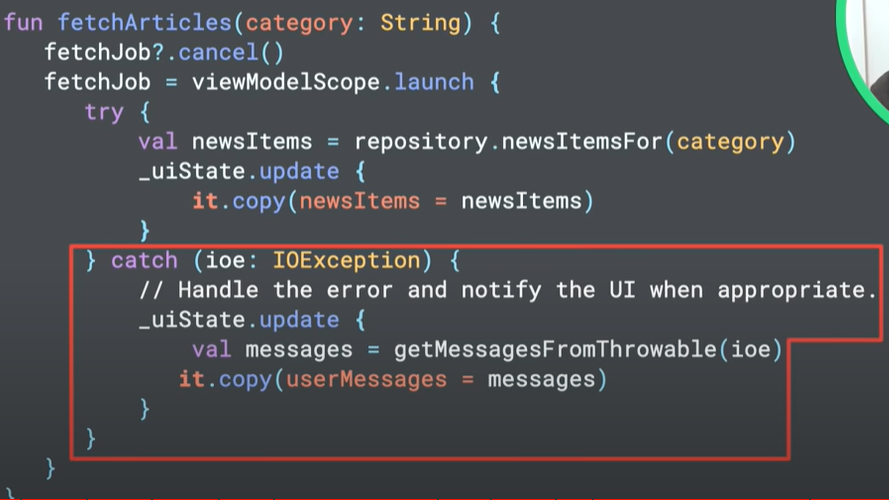
El código es un poco lioso todavía pero lo iremos viendo en los codelabs …
Respecto a la lógica de negocios, podríamos clasificarla en dos categorías principales:
- Código que resuelve qué hacer con los cambios de estado
- Se manejar este tipo de lógica de negocios en las capas de dominio y datos.
- Código que resuelve cómo mostrar los cambios de estado
- La capa de la interfaz de usuario debe administrar esta lógica de comportamiento de la interfaz de usuario, como implementar la lógica de navegación o mostrar mensajes al usuario.
A menudo, los StateHolders como los ViewModels viven mucho más que las IU que los observan.
Por lo tanto, debe asegurarse de que no estén observando el estado de la interfaz de usuario cuando no se pueden ver.
El tipo ViewModel es la implementación recomendada para la gestión del estado de la interfaz de usuario a nivel de pantalla con acceso a la capa de datos.
El consumo del estado de la interfaz de usuario se realiza con el operador de la terminal en el tipo de datos observable.
Por ejemplo, si usa LiveData, este es el método observe(). Si se usan los flujos de Kotlin (Kotlin Flows in Android), este es el método collect() .
Mientras observa y consume el estado de la interfaz de usuario en la interfaz de usuario, no debe ignorar el ciclo de vida de la interfaz de usuario.
Un objeto de estado de la interfaz de usuario debe controlar los estados que están relacionados entre sí.
En las aplicaciones de Jetpack Compose, puede usar las API de estado observables de Compose , como mutableStateOf o snapshotFlow para la exposición del estado de la interfaz de usuario.
Capa de datos
La capa de datos de una app contiene la lógica de negocio.
Esta lógica es lo que hay que hacer con tu App y que se diferencia de otras.
Está compuesta por reglas que determinan cómo tu app crea, almacena y cambia datos. Las reglas las defines tu como programador.
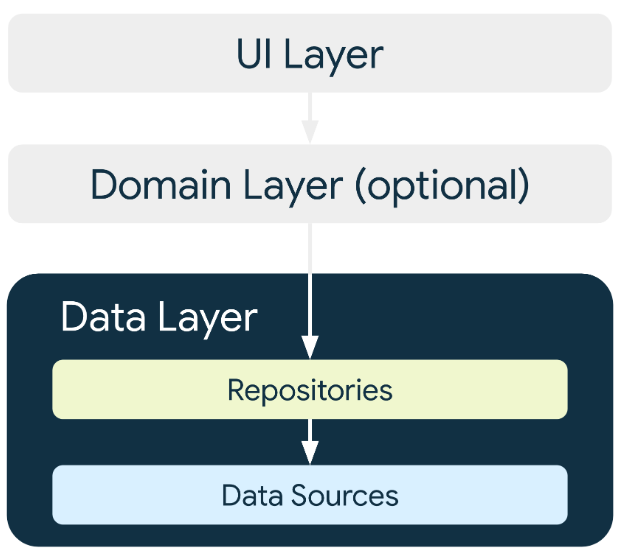
La capa de datos está formada por repositorios que pueden contener de cero a muchas fuentes de datos.
Debes crear una clase de Repositorio para cada tipo de datos diferente que administres en tu app.
Por ejemplo, puedes crear una clase MoviesRepository para datos relacionados con películas o una clase PaymentsRepository para datos relacionados con pagos.
Las clases de repositorio son responsables de las siguientes tareas:
- Exponer datos al resto de la app
- Centralizar los cambios en los datos
- Resolver conflictos entre múltiples fuentes de datos
- Abstraer fuentes de datos del resto de la app
- Contener la lógica de negocio
Cada clase de Data Source debe tener la responsabilidad de trabajar con una sola fuente de datos, que puede ser un archivo, una fuente de red o una base de datos local, etc.
Las clases Data Source son el puente entre la aplicación y el sistema para las operaciones de datos.
Detalles de la capa de Datos
La responsabilidad principal de la capa de datos es Almacenar, manejar y proporcionar acceso a los datos de la aplicación.
Las clases de esta capa suelen llamarse: type_of_data + Repository
Básicamente consiste en Datos de Aplicación y Modelo de negocio.
Especifica cómo deben crearse, almacenarse y modificarse los datos.
De hecho esta capa está compuesta por distintos Repositorios los cuales pueden interactuar con fuentes de datos de distintos tipos.
Los repositorios se responsabilizan de trabajar únicamente con una fuente de datos que generalmente mantienen una unidad/entidad del modelo de negocio.
Las fuentes de datos (Data Sources) pueden ser locales o remotas.
Los repositorios centralizan la funcionalidad de acceso, proporcionan mejor mantenimiento y desacoplan la tecnología (o infraestrucruta de acceso a los datos) del resto de capas.
Se pude crear un Repositorio para cada tipo de dato (de negocio) que vas a manejar en tu aplicación de Android.
Las otras capas de la Arquitectura de la App no deben de acceder directamente a las fuentes de datos.
Por tanto el punto de entrada a los datos en la aplicación son las clases Repositorio.
Inicialmente un Repositorio (una clase) define operaciones con los datos.
Puedes detectar modificaciones en los datos a lo largo del tiempo si usamos un data stream (un flujo de datos), como por ejemplo usando los Kotlin Flows.
Los datos que ofrece el repositorio deben ser siempre aquellos que vienen de la SSOT (Single Source of Truth) directamente.
Si hay un conflicto entre los datos locales en tu base de datos y en el servidor, el Repositorio debe identificarlo y solucionarlo eficientemente.
Los datos expuestos por el Data Layer deben ser Inmutables.
Por tanto todas las clases de esta capa no pueden manipularlos.
Otro beneficio de que los datos sean inmutables es que pueden ser manejados con seguridad por distintos threads.
El Repositorio puede construirse desde distintas fuentes de datos, cuando necesites tener distintos niveles de repositorios en algunas situaciones complejas.
Una solución para la gestión de errores es permitir la propagación de excepciones con funciones suspend.
Puedes usar bloques try/catch desde la UI layer o la Domain Layer, o bien si usas Flows utilizar el operador catch.
En cualquier caso debes gestionar eficientemente los errores que ocurren en la Data Layer.
Capa de dominio
La capa de dominio es una capa opcional que se ubica entre la capa de la IU y la de datos.
La capa de dominio es responsable de encapsular la lógica de negocio compleja o la lógica de negocio simple que varios ViewModels van a reutilizar.
Esta capa es opcional porque no todas las apps tendrán estos requisitos. Solo debes usarla cuando sea necesario; por ejemplo, para administrar la complejidad o favorecer la reutilización.
Nota : Sin embargo hay corrientes de la Arquitectura de Apps que promueven mover la lógica de negocio a la capa de Dominio y dejar en la Capa de Datos sólo lo necesario para lidiar con los datos y sus fuentes diversas. En cada App, según su complejidad podemos mover la lógica de negocio entre estas dos capas.
Las clases de esta capa se denominan casos de uso o interactores. Cada caso de uso debe tener responsabilidad sobre una funcionalidad única.
Detalles de la capa de Dominio
El objetivo principal es encapsular la lógica de negocio compleja, o la lógica de negocio que es reutilizada por multiples StateHolders (Viewmodels)
No se encarga de cómo se muestran los datos, eso es el trabajo del UI Layer, y tampoco es responsable de almacenar o acceder a los datos, eso es trabajo de la Data Layer.
Algunas ventajas de usar un Domain Layer (recordar que es opcional) son:
- Hace más fácil conseguir el principio de separación de problemas y responsabilidades aumentando la modularización.
- Incrementa la legibilidad de las clases que usan esta capa
- Facilita la ejecución de tests en la aplicación android gracias a la modularización.
Una responsabilidad del Domain Layer es almacenar los Casos de Uso
Normalmente las clases que contiene se llaman Interactuadores (Interactors) o Casos de Uso (Use Cases)
Cada caso de uso se responsabiliza únicamente de una tarea y NO debe incluir datos mutables.
La convención para nombrar las clases suele ser: verb in present tense + noun/what (optional) + UseCase
Si se requiere cachear datos, esta lógica de almacenamiento en cache se debe llevar a la Data Layer.
Las clases de Casos de Uso pueden depender de clases de niveles inferiores, como repositorios en el Data Layer y de otras clases de Casos de Uso, pero NO deben depender de clases de niveles superiores en la arquitectura como los ViewModels.
Los Casos de Uso consisten en código reusable. Por tanto pueden ser usadas por otros Casos de Uso siendo incluso normal establecer Casos de Uso en distintos niveles dentro del Domain Layer.
Los casos de uso sólo hacen una tarea.
Cuando pasas tu caso de uso como dependencia, como cuando se construye un ViewModel, en el ViewModel se puede llamar como una función normal.
Los Casos de Uso no tienen su Life Cycle propio, pero están anclados al ámbito de la clase que los usa (scoped to the caller)
La Casos de Uso del Domain Layer deben ser main-safe.
Esto significa que debe ser seguro llamarlos desde el main-thread de la aplicación.
Si un caso de uso debe realizar una operación costosa (long-running blocking operation) se debe mover a un Background Thread (o Corrutina)
Si tienes código que se utiliza en distintos ViewModels hay que poner dicho código dentro de un Caso de Uso.
De esta forma sólo se modifica el código en un único sitio (encapsulación).
Otra responsabilidad del Domain Layer es la combinación/gestión de datos de múltiples repositorios.
Esto evita que nuestro ViewModel contenga código de gestión, conversión, tratamiento etc.. de los datos de distintas fuentes y se pueda construir con los datos ya preparados por el Domain Layer como una unidad testable.
Los Casos de Uso toman como dependencias los distintos repositorios y los dispatchers (código a ejecutar) a ser usados como trabajo de segundo plano.
Forzar toda la lógica de negocio como como casos de uso en el Domain Layer nos ofrece los siguientes beneficios:
- Evita que pueda saltarse la propia Domain Layer, ya que todo lo necesario para modelar las acciones negocio de mi aplicación ya se encuentra disponible en la capa de dominio.
- Hace que los ViewModels sean más fáciles de probar.
Pero esto incrementa la complejidad del código en esta capa, es el precio a pagar.
Cómo administrar dependencias entre componentes
Las clases de tu app dependen de otras para funcionar correctamente.
Puedes usar cualquiera de los siguientes patrones de diseño para recopilar las dependencias de una clase en particular:
- Inserción de dependencia (DI): Permite que las clases definan sus dependencias sin construirlas.
En el tiempo de ejecución, otra clase es responsable de proporcionar estas dependencias. - Localizador de servicios: Su patrón brinda un registro en el que las clases pueden obtener sus dependencias en lugar de construirlas.
Estos patrones te permiten hacer un escalamiento del código, ya que proporcionan patrones claros para administrar dependencias sin duplicar el código ni aumentar la complejidad. Además, te permiten cambiar rápidamente entre las implementaciones de prueba y de producción.
Android seguir los patrones de inserción de dependencia y usar la biblioteca Hilt en las apps para Android.
Hilt construye automáticamente objetos con un recorrido del árbol de dependencias, proporciona garantías de tiempo de compilación sobre dependencias y crea contenedores de dependencias para clases de framework de Android.
Prácticas recomendadas generales
La programación es una disciplina creativa y crear apps de Android no es una excepción.
Hay muchas maneras de resolver un problema: puedes comunicar datos entre varias actividades o fragmentos, recuperar datos remotos y conservarlos a nivel local para el modo sin conexión, o bien controlar cualquier cantidad de situaciones comunes con las que pueden encontrarse las apps no triviales.
Aunque las siguientes recomendaciones no son obligatorias, en la mayoría de los casos, si las sigues, tu código base será más confiable, tendrá mayor capacidad de prueba y será más fácil de mantener a largo plazo.
No almacenes datos en los componentes de la app
Evita designar los puntos de entrada de tu app (receptores de emisiones, servicios y actividades) como fuentes de datos. En cambio, solo deben coordinar con otros componentes para recuperar el subconjunto de datos relevante para ese punto de entrada. Cada componente de la app tiene una duración relativamente corta, según la interacción que el usuario tenga con su dispositivo y el estado general del sistema en ese momento.
Reduce las dependencias de clases de Android
Los componentes de tu app deben ser las únicas clases que dependan de las APIs del SDK del framework de Android, como Context o Toast. La abstracción de otras clases en tu app fuera de ellas ayuda con la capacidad de prueba y reduce el acoplamiento dentro de la app.
Crea límites de responsabilidad bien definidos entre varios módulos de tu app.
Por ejemplo, no extiendas el código que carga datos de la red entre varias clases o paquetes en tu código base. Del mismo modo, no definas varias responsabilidades no relacionadas, como caché de datos y vinculación de datos, en la misma clase. Podría ser útil que siguieras la arquitectura de la app recomendada.
Expón lo mínimo indispensable de cada módulo
Por ejemplo, no caigas en la tentación de crear un acceso directo que exponga un detalle interno de la implementación de un módulo. Quizás ahorres algo de tiempo a corto plazo, pero tendrás más probabilidades de que se generen problemas técnicos a medida que tu código base evolucione.
Concéntrate en aquello que hace única a tu app para que se destaque del resto
No desperdicies tu tiempo reinventando algo que ya existe ni escribiendo el mismo código estándar una y otra vez. En cambio, enfoca tu tiempo y tu energía en aquello que hace que tu app sea única y deja que tanto las bibliotecas de Jetpack como las otras recomendadas se ocupen del código estándar repetitivo.
Piensa en cómo lograr que cada parte de tu app se pueda probar por separado
Por ejemplo, una API bien definida para recuperar datos de la red facilitará las pruebas que realices en el módulo que conserve esa información en la base de datos local. En cambio, si combinas la lógica de estos dos módulos en un solo lugar, o bien si distribuyes el código de red por todo tu código base, será mucho más difícil (y quizás hasta imposible) ponerlo a prueba eficazmente.
Los tipos son responsables de su política de simultaneidad
Conserva la mayor cantidad posible de datos relevantes y actualizados
De esa manera, los usuarios podrán aprovechar la funcionalidad de tu app, incluso cuando su dispositivo esté en modo sin conexión. Recuerda que no todos tus usuarios cuentan con una conexión de alta velocidad de manera constante y, si lo hacen, pueden tener una mala recepción en lugares muy concurridos.